7.1. Parameter estimation#
Keywords: parameter estimation, ipopt usage, data fitting
This notebook demonstrates parameter estimation for the catalytic oxidation experiment conducted in the senior Chemical Engineering Laboratory course at Notre Dame. The reaction can be modeled as
where concentration of \(\cal{A}\) is measured in the reactor feed and effluent streams. This reactor, with high internal recycle, operates in the stirred tank reactor regime.
7.1.1. Imports#
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import random
import scipy.stats as stats
import scipy.optimize as optimize
import shutil
import sys
import os.path
if not shutil.which("pyomo"):
!pip install -q pyomo
assert(shutil.which("pyomo"))
if not (shutil.which("ipopt") or os.path.isfile("ipopt")):
if "google.colab" in sys.modules:
!wget -N -q "https://ampl.com/dl/open/ipopt/ipopt-linux64.zip"
!unzip -o -q ipopt-linux64
else:
try:
!conda install -c conda-forge ipopt
except:
pass
assert(shutil.which("ipopt") or os.path.isfile("ipopt"))
from pyomo.environ import *
7.1.2. Steps in model fitting#
The goal of parameter estimation is to use experimental data to estimate values of the unknown parameters in model describing the system of interest, and to quantify uncertainty associated with those estimates.
Following the outline in “Model Fitting and Error Estimation”, Costa, Kleinstein, Hershberg:
Assemble the data in useful data structures. Plot the data. Be sure there is meaningful variations to enable parameter estimation.
Select an appropriate model based on underlying theory. Identify the known and unknown parameters.
Define a “figure of merit” function the measures the agreement of model to data for given value of the unknown parameters.
Adjust the unknown parameters to find the best fit. Generally this involves minimizing the figure of merit function.
Evaluate the “Goodness of Fit”. Test assumptions of randomness, and for systematic deviations between the model and data.
Estimate the accuracy of the best-fit parameters. Provide confidence intervals and covariance among unknown parameters.
Determine whether a better fit is possible.
This notebook uses the Pandas package to encapsulate and display experimental data. Pandas is a comprehensive Python package for managing and displaying data. It provides many useful and time-saving tools for performing common operations on data.
7.1.3. Step 1. The data#
The following data is taken from [“Lecture Notes for CBE 20258” by Prof. David Leighton]. The data consists of measurements done for three different feed concentrations C0. For each feed concentration, students adjust reactor temperature T using an external heat source, then measure the reactor exit concentration C.
For convenience, the data is first encoded as a nested Python dictionary. The first index refers to the name of the experiment. The data for each experiment is then encoded as a nested dictionary with name, value pairs. The values are strings, numbers, or lists of measured responses. The name of the experiment is repeated to facilitate conversion to a Pandas data frame.
data = {
'Expt A': {
'Expt': 'A',
'C0' : 1.64E-4,
'T' : [423, 449, 471, 495, 518, 534, 549, 563],
'C' : [1.66e-4, 1.66e-4, 1.59e-4, 1.37e-4, 8.90e-5, 5.63e-5, 3.04e-5, 1.71e-5],
},
'Expt B': {
'Expt': 'B',
'C0' : 3.69e-4 ,
'T' : [423, 446, 469, 490, 507, 523, 539, 553, 575],
'C' : [3.73e-4, 3.72e-4, 3.59e-4, 3.26e-4, 2.79e-4, 2.06e-4, 1.27e-4, 7.56e-5, 3.76e-5],
},
'Expt C': {
'Expt': 'C',
'C0' : 2.87e-4,
'T' : [443, 454, 463, 475, 485, 497, 509, 520, 534, 545, 555, 568],
'C' : [2.85e-4, 2.84e-4, 2.84e-4, 2.74e-4, 2.57e-4, 2.38e-4, 2.04e-4, 1.60e-4, 1.12e-4,
6.37e-5, 5.07e-5, 4.49e-5],
},
}
The following cell converts the data dictionary of experimental data to a Pandas dataframe then prints the result.
df = pd.concat([pd.DataFrame(data[expt]) for expt in data])
df = df.set_index('Expt')
print(df)
C0 T C
Expt
A 0.000164 423 0.000166
A 0.000164 449 0.000166
A 0.000164 471 0.000159
A 0.000164 495 0.000137
A 0.000164 518 0.000089
A 0.000164 534 0.000056
A 0.000164 549 0.000030
A 0.000164 563 0.000017
B 0.000369 423 0.000373
B 0.000369 446 0.000372
B 0.000369 469 0.000359
B 0.000369 490 0.000326
B 0.000369 507 0.000279
B 0.000369 523 0.000206
B 0.000369 539 0.000127
B 0.000369 553 0.000076
B 0.000369 575 0.000038
C 0.000287 443 0.000285
C 0.000287 454 0.000284
C 0.000287 463 0.000284
C 0.000287 475 0.000274
C 0.000287 485 0.000257
C 0.000287 497 0.000238
C 0.000287 509 0.000204
C 0.000287 520 0.000160
C 0.000287 534 0.000112
C 0.000287 545 0.000064
C 0.000287 555 0.000051
C 0.000287 568 0.000045
It’s generally a good idea to create some initial displays of the experimental data before attempting to fit a mathematical model. This provides an opportunity to identify potential problems with data, observe key features, and look for particular symmetries or patterns in the data.
for expt in sorted(set(df.index)):
plt.scatter(df['T'][expt], df['C'][expt])
plt.ylim(0, 1.1*max(df['C']))
plt.xlabel('temperature / K')
plt.ylabel('concentration')
plt.legend(["Expt. " + expt for expt in sorted(set(df.index))])
plt.title('Effluent Concentrations');
plt.grid(True)
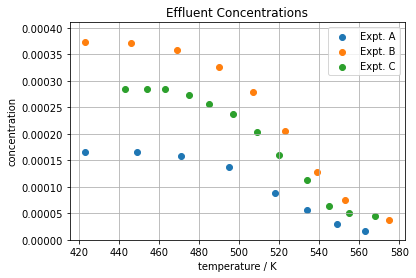
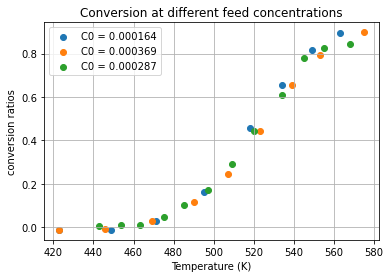
An initial plot of the data shows the effluent concentration decreases at higher operating temperatures. This indicates higher conversion at higher temperatures. A plot of conversion X
collapses the data into a what appears to be a single function of temperature. The following cell adds conversion as an additional column of the data set.
# add a column 'X' to the dataframe
df['X'] = 1 - df['C']/df['C0']
for expt in sorted(set(df.index)):
plt.scatter(df['T'][expt], df['X'][expt])
plt.xlabel('Temperature (K)')
plt.ylabel('conversion ratios')
plt.legend(['C0 = ' + str(list(df['C0'][expt])[0]) for expt in sorted(set(df.index))])
plt.title('Conversion at different feed concentrations');
plt.grid(True)
7.1.4. Step 2. Select a model#
A proposed steady-state model for the catalytic reactor is
The known parameters are the flow rate \(q\), the mass of catalysit \(m\), and a reference temperature \(T_r\). The ratio \(\frac{T}{T_r}\) is the ‘reduced temperature’ and provides for a better conditioned equation. The unknown parameters are the reaction order \(n\), the Arrhenius pre-exponental factor \(k_0\), and the reduced activation energy \(\frac{E_a}{R T_r}\). Generally the pre-exponential factor is very large, therefore is combined within the exponential term as \(\ln k_0\).
The unknown parameters are:
Parameter |
Code |
Description |
|---|---|---|
\(n\) |
|
reaction order |
\(\ln k_0\) |
|
natural log of Arrenhius pre-exponential factor |
\(\frac{E_a}{R T_r}\) |
|
reduced activation energy |
7.1.5. Step 3. Define a “figure of merit”#
Each experimental measure consists of values of the unknown parameters and experimental values \(C_{0,k}\), \(T_k\), and \(C_k\). Given estimates for the unknown parameters, the model equation provides a convenient definition of a residual \(r_k\) as
If the model is an accurate depiction of the reaction processes then we expect the residuals to be small, random variates.
Tr = 298 # reference temperature.
q = 0.1 # flow rate (liters/min)
m = 1 # amount of catalyst (g)
def residuals(parameters, df):
n, lnk0, ERTr = parameters
C0, C, T = df['C0'], df['C'], df['T']
return C0 - C - (m/q) * C**n * (T/Tr)**n * np.exp(lnk0 - ERTr*Tr/T)
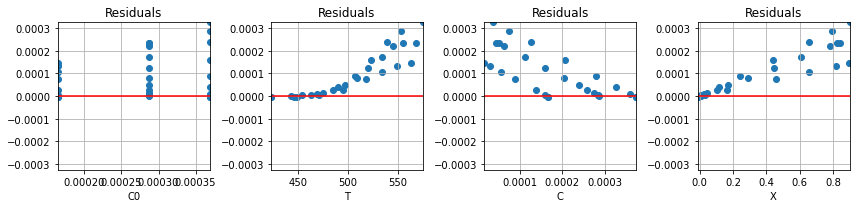
To illustrate, the following cell calculates the residuals for an initial estimate for the unknown parameter values. The residuals are then plotted as a function of the experimental variables to see if the residuals behave as random variates.
parameter_names = ['n', 'lnk0', 'ERTr']
parameter_guess = [1, 15, 38]
def plot_residuals(r, df, ax=None):
rmax = np.max(np.abs(r))
if ax is None:
fig, ax = plt.subplots(1, len(df.columns), figsize=(12,3))
else:
rmax = max(ax[0].get_ylim()[1], rmax)
n = 0
for c in df.columns:
ax[n].scatter(df[c], r)
ax[n].set_ylim(-rmax, rmax)
ax[n].set_xlim(min(df[c]), max(df[c]))
ax[n].plot(ax[n].get_xlim(), [0,0], 'r')
ax[n].set_xlabel(c)
ax[n].set_title('Residuals')
ax[n].grid(True)
n += 1
plt.tight_layout()
r = residuals(parameter_guess, df)
plot_residuals(r, df)
7.1.6. Step 4. Find a best fit#
A least squares ‘figure of merit’ for the fit of the model to the experimental data is given by
Our goal is to find values for the unknown parameters that minimize the sum of the squares of the residuals.
The following cell defines two functions. The first is sos which calculates the sum of squares of the residuals. The best_fit function uses scipy.optimize.fmin
def sos(parameters, df):
return sum(r**2 for r in residuals(parameters, df))
def best_fit(fcn, df, disp=1):
return optimize.fmin(fcn, parameter_guess, args=(df,), disp=disp)
parameter_fit = best_fit(sos, df)
for name,value in zip(parameter_names, parameter_fit):
print(name, " = ", round(value,2))
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 140
Function evaluations: 257
n = 0.65
lnk0 = 13.65
ERTr = 34.21
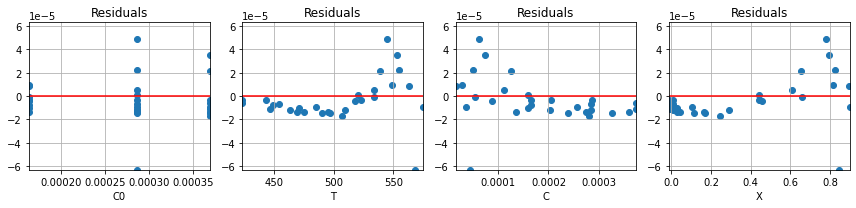
Let’s compare how the residuals have been reduced as a result of minimizing the sum of squares.
ax = plot_residuals(residuals(parameter_guess, df), df)
plot_residuals(residuals(parameter_fit, df), df, ax=ax);
7.1.7. Step 5. Evaluate the goodness of fit#
7.1.7.1. Plotting residuals#
An important element of any parameter fitting exercise is to examine the residuals for systematic errors. The following cell plots the residuals as functions of .
r = residuals(parameter_fit, df)
plot_residuals(r, df);
It’s apparent that there is systematic error in the residuals. To cause the minimizer to put more weight on those large residuals, a scaling factor is introduced into the norm used to measure the residual for the purpose of parameter estimation.
7.1.7.2. Separable model#
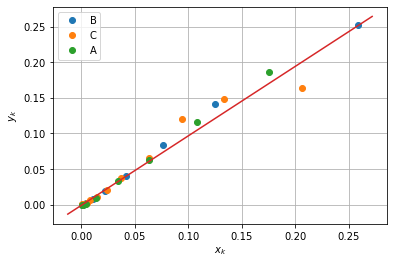
An interesting feature of the model for the catalytic reactor is that it can be separated into two sides such that the right-hand side is a function only of \(T\).
Note that the left-hand side is a function of two independent experimental variables. But if the model accurately represents experimental behavior, then a plot of the left-hand side versus temperature should collapse to a single curve.
The next cell plots the experimental data as pairs \((x_k, y_k)\) where
If the fitted model is an accurate representation of the catalytic reactor, then the data should collapse to single curve aligned with diagonal.
n, lnk0, ERTr = parameter_fit
for expt in set(df.index):
y = (df['C0'][expt] - df['C'][expt])/df['C'][expt]**n
x = (m/q) * (df['T'][expt]/Tr)**n * np.exp(lnk0 - ERTr*Tr/df['T'][expt])
plt.plot(x, y, marker='o', lw=0)
plt.plot(plt.xlim(), plt.ylim())
plt.ylabel('$y_k$')
plt.xlabel('$x_k$')
plt.legend(set(df.index))
plt.grid(True)
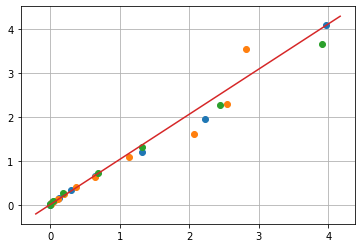
Substituting \(C = C_0(1-X)\)
for expt in set(df.index):
y = df['C0'][expt]**(n-1) * (m/q) * (df['T'][expt]/Tr)**n * np.exp(lnk0 - ERTr*Tr/df['T'][expt])
x = df['X'][expt]/(1 - df['X'][expt])**n
plt.plot(x, y, marker='o', lw=0)
plt.plot(plt.xlim(), plt.ylim())
plt.xlabel('')
plt.grid(True)
7.1.8. Step 6. Estimate confidence intervals#
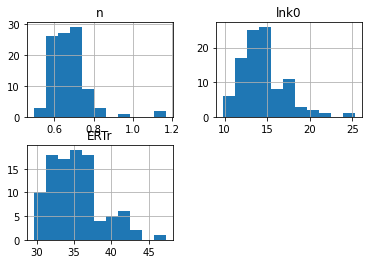
The following cell implements a simple bootstrap method for estimating confidence intervals for the fitted parameters. The function resample creates a new dataframe of data by sampling (with replacement) the original experimental data.
The best_fit function is called N times on resampled data sets to create a statistical sample of fitted parameters. Those results are analyzed using statistical functions from the Pandas library.
def resample(df):
return df.iloc[random.choices(range(0, len(df)), k=len(df))]
N = 100
dp = pd.DataFrame([best_fit(sos, resample(df), disp=0) for k in range(0,N)], columns=parameter_names)
print('Mean values and 95% confidence interval')
for p in dp.columns:
print(p, " = ", round(dp[p].mean(),2), " +/- ", round(1.96*dp[p].std(),2))
dp.hist(bins=1+int(np.sqrt(N)))
print("\n\nQuantiles")
dp.quantile([0.05, .5, 0.95]).T
Mean values and 95% confidence interval
n = 0.68 +/- 0.2
lnk0 = 14.46 +/- 5.13
ERTr = 35.27 +/- 6.69
Quantiles
| 0.05 | 0.50 | 0.95 | |
|---|---|---|---|
| n | 0.563790 | 0.666206 | 0.814233 |
| lnk0 | 11.050461 | 14.096802 | 18.641407 |
| ERTr | 30.632469 | 34.671630 | 41.664595 |
7.1.9. Step 7. Determine if a better fit is possible#
In this section we introduce an alternative method of coding solutions to parameter estimation problems using Pyomo. An advantage of using Pyomo is the more explicit indentification of unknown parameters, objective, and constraints on parameter values.
7.1.9.1. Pyomo model - version 1#
The first version of a Pyomo model for estimating parameters for the catalytic reactor is a direct translation of the approach outlined above. There are some key coding considerations in performing this translation to a Pyomo model:
As of the current version of Pyomo, an optimization variable cannot appear in the exponent of an expresson. The workaound is to recognize $\( C^n = e^{n \ln C}\)$
The residuals are expressed as a list of Pyomo expressions.
Tr = 298 # The reference temperature.
q = 0.1 # The flow rate (liters/min)
m = 1 # The amount of catalyst (g)
def pyomo_fit1(df):
T = list(df['T'])
C = list(df['C'])
C0 = list(df['C0'])
mdl = ConcreteModel()
mdl.n = Var(domain=Reals, initialize=1)
mdl.lnk0 = Var(domain=Reals, initialize=15)
mdl.ERTr = Var(domain=Reals, initialize=38)
residuals = [
C0[k] - C[k] - (m/q) * exp(mdl.n*log(C[k])) * exp(mdl.n*log(T[k]/Tr)) * exp(mdl.lnk0 - mdl.ERTr*Tr/T[k])
for k in range(len(C))]
mdl.obj = Objective(expr=sum(residuals[k]**2 for k in range(len(C))), sense=minimize)
SolverFactory('ipopt').solve(mdl)
return [mdl.n(), mdl.lnk0(), mdl.ERTr()], [residuals[k]() for k in range(len(C))]
parameter_values_1, r1 = pyomo_fit1(df)
plot_residuals(r1, df)
for name,value in zip(parameter_names, parameter_values_1):
print(name, " = ", round(value,2))
n = 0.65
lnk0 = 13.65
ERTr = 34.21
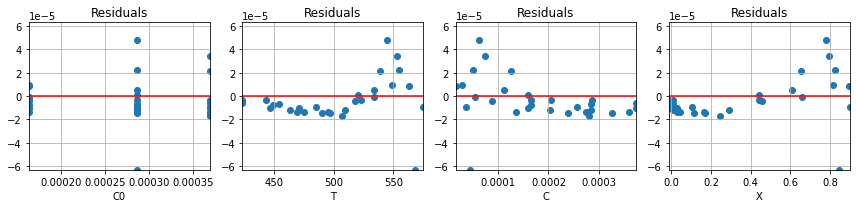
7.1.9.2. Pyomo model - version 2#
As a second model we consider a somewhat simpler model that omits the temperature dependence of the Arrhenius pre-exponential factor:
Can this somewhat simpler model adequately fit the data?
Tr = 298 # The reference temperature.
q = 0.1 # The flow rate (liters/min)
m = 1 # The amount of catalyst (g)
def pyomo_fit2(df):
T = list(df['T'])
C = list(df['C'])
C0 = list(df['C0'])
mdl = ConcreteModel()
mdl.n = Var(domain=Reals, initialize=1)
mdl.lnk0 = Var(domain=Reals, initialize=15)
mdl.ERTr = Var(domain=Reals, initialize=38)
residuals = [
C0[k] - C[k] - (m/q) * exp(mdl.n*log(C[k])) * exp(mdl.lnk0 - mdl.ERTr*Tr/T[k])
for k in range(len(C))]
mdl.obj = Objective(expr=sum(residuals[k]**2 for k in range(len(C))), sense=minimize)
SolverFactory('ipopt').solve(mdl)
return [mdl.n(), mdl.lnk0(), mdl.ERTr()], [residuals[k]() for k in range(len(C))]
parameter_values_2, r2 = pyomo_fit2(df)
plot_residuals(r2, df)
for name,value in zip(parameter_names, parameter_values_2):
print(name, " = ", round(value,2))
n = 0.65
lnk0 = 14.69
ERTr = 35.4
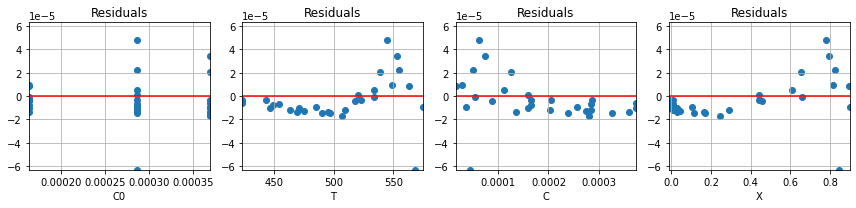
Is there a meaningful difference between these two models?
ax = plot_residuals(r2, df)
plot_residuals(r1, df, ax=ax);
plt.hist(r1, color='b', alpha=0.5)
plt.hist(r2, color='y', alpha=0.5)
plt.legend(['temperature dependent pre-exponential', 'no temperature dependent pre-exponential'])
<matplotlib.legend.Legend at 0x7fb57e799250>
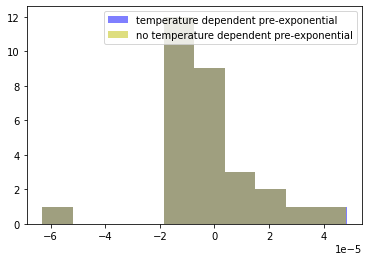
Based on this analysis of residuals, there is very little statistical support for a temperature dependent Arrhenius pre-exponential factor. Generally speaking, in situations like this it is generally wise to go with the simplist (i.e, most parsimonious) model that can adequately explain the data.
7.1.9.3. Pyomo model - version 3#
Is the reaction \(n^{th}\) order, or could it be satisfactorily approximated with first-order kinetics?
The following cell adds a constraint to force \(n=1\). We’ll then examine the residuals to test if there is a statistically meaningful difference between the case \(n=1\) and \(n \ne 1\).
Tr = 298 # The reference temperature.
q = 0.1 # The flow rate (liters/min)
m = 1 # The amount of catalyst (g)
def pyomo_fit3(df):
T = list(df['T'])
C = list(df['C'])
C0 = list(df['C0'])
mdl = ConcreteModel()
mdl.n = Var(domain=Reals, initialize=1)
mdl.lnk0 = Var(domain=Reals, initialize=15)
mdl.ERTr = Var(domain=Reals, initialize=38)
residuals = [
C0[k] - C[k] - (m/q) * exp(mdl.n*log(C[k])) * exp(mdl.lnk0 - mdl.ERTr*Tr/T[k])
for k in range(len(C))]
mdl.obj = Objective(expr=sum(residuals[k]**2 for k in range(len(C))), sense=minimize)
mdl.con = Constraint(expr = mdl.n==1)
SolverFactory('ipopt').solve(mdl)
return [mdl.n(), mdl.lnk0(), mdl.ERTr()], [residuals[k]() for k in range(len(C))]
parameter_values_3, r3 = pyomo_fit3(df)
plot_residuals(r3, df)
for name,value in zip(parameter_names, parameter_values_3):
print(name, " = ", round(value, 2))
n = 1.0
lnk0 = 23.01
ERTr = 44.59
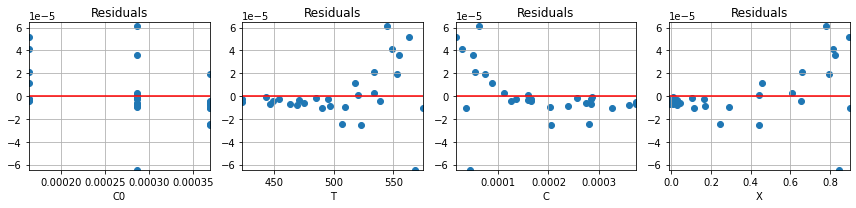
Comparing to models above, we see that restricting \(n=1\) does lead to somewhat larger residuals.
ax = plot_residuals(r3, df)
plot_residuals(r2, df, ax=ax);
plt.hist(r2, color='b', alpha=0.5)
plt.hist(r3, color='y', alpha=0.5)
plt.legend(['nth order kinetics', 'first order kinetics'])
plt.grid(True)
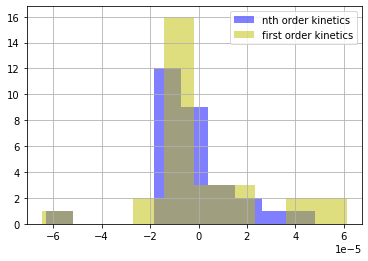
7.1.9.4. F-ratio test#
r2 = np.array(r2)
df2 = len(r2) - 1 - 3 # degrees of freedom after fitting 3 parameters
r3 = np.array(r3)
df3 = len(r3) - 1 - 3 # degrees of freedom after fitting 2 parameters
Fratio = r2.var()/r3.var()
pvalue = stats.f.cdf(Fratio, df2, df3)
if pvalue > 0.05:
print("Cannot reject hypothesis that the variances are equal at p=0.05: Test pvalue = ", pvalue)
Cannot reject hypothesis that the variances are equal at p=0.05: Test pvalue = 0.13297014615598618
7.1.9.5. Levene test#
The Levene test provides a more robust test for the null hypothesis that samples are from populations with equal variances.
stats.levene(r2, r3)
LeveneResult(statistic=0.3449520288649278, pvalue=0.559345414685297)
The Levene statistic means that we cannot rule out that the residuals of these models have different variances. Consequently we do not have statistically meaningful evidence that the order of the reaction is different from \(n=1\).